As aggregators and recommendation systems mature in their ability to match content to people, it changes how we consider the design of these products. In this post we’ll discuss the balance between transparency and function, using the ‘match-based’ recommendation system used by Netflix and Google as an example.

Match-makers: Personalised product recommendations based on AI and machine learning
Over the past few years we’ve seen a gradual shift away from user reviews to ratings as the primary method for helping people to make choices. The movement away from user reviews, is because it gives a product a fairly obvious understandable feedback loop - the more I like this thing, the more of that thing I will see or hear.
More and more, organisations are relying on AI and machine learning serving recommendations based on the behaviour of individual users. This means products can provide tailored, personalised recommendations at scale, without the need for users to write reviews or give ratings. But this comes at a cost - transparency on why the content is a ‘match’.
Netflix shelved star-ratings entirely last year and now relies entirely on automated, algorithm-based recommendations - whereby Netflix recommends a film to you based on your viewing habits and provides a % score for how well it believes it aligns to your tastes. Google has recently followed suit in Google Maps with its recommendations for Places (e.g. restaurants, bars, attractions etc). In both systems, very little explanation is provided back to users on how the score is calculated or how the decision was reached.To follow through with the dating analogy, it’s a bit like a blind date. And blind dates are always a bad idea.
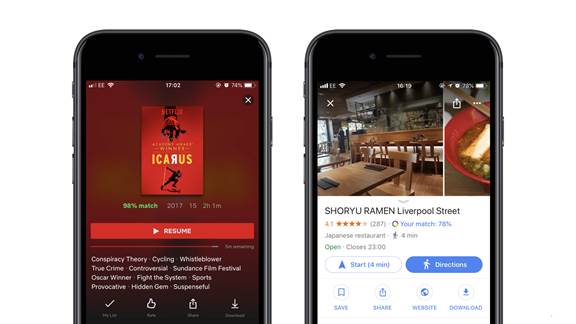
Netflix were criticised at the time for removing user reviews and forcing people to use the match system to make a decision. Generally this criticism centred on the lack of transparency in letting the user know how the % score was calculated.
There are established patterns for improving the design of products when people find them confusing to use. Good practice typically dictates that products should provide feedback to users when they’ve performed an action, so they know what the impact or outcome was. This could be as small as displaying an icon for a successful or failed file upload, or in more complex scenarios, outlining the information needed or missing at each stage of a mortgage application, for example.
There is normally a correlation between how usable a solution is, with how consistent we are in presenting information throughout a process. In other words, the more transparent we are with users of a product, the lower the chance of them getting confused or encountering a problem they can’t solve themselves.
In the context of bigger datasets and increasingly sophisticated automation, you would naturally expect usability to have a more important part to play. In DARPA’s words, how can we create ‘explainable artificial intelligence’.
But in reality, it’s really difficult to provide feedback for a couple of reasons:
- The models used are often referred to as being ‘black-box’ - it’s hard for us to unpack the process that an AI and machine learning-model has gone through to reach a decision.
- Even if we have a system that outlines the process - visualising and presenting that information in a way that is easily digestible by the user is often challenging due to the sheer scale and complexity of data involved.
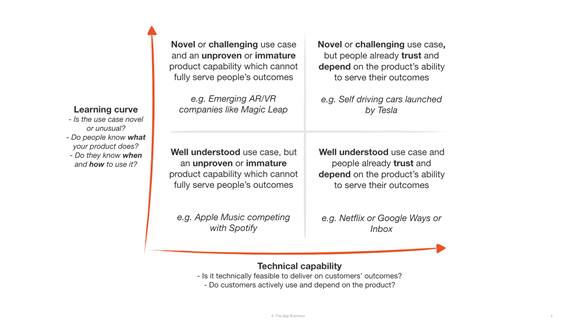
Consider the learning curve for use cases and the technical capability to deliver against them before defining your approach.
In a world where it is fast becoming an expectation for products to provide a tailored or contextual experience, it’s more important than ever to carefully prioritise the products or features to invest in.
Identifying how challenging the use case is and the technical capability required to deliver it can be a useful first step in deciding where to invest efforts or the approach to take:
Although it’s easy to criticise companies like Netflix for limiting the feedback provided with its recommendations, it can be argued that it doesn’t actually hinder how relevant its recommendations are on users’ overall experience with the product.
I’d argue that companies like Netflix or Spotify don’t need to be completely transparent, as they are able to deliver content people want through the capability of their recommendation engines. As long as they can deliver on the promise of surfacing content that users love, people won’t worry about how those recommendations are arrived at, and will come to love the lower effort compared to explicit recommendation systems.
The contrasting case is Apple, who has been playing catch-up with Spotify from an AI and machine learning perspective. As Apple can’t yet deliver the same kind of recommendation experience their competitors can, they recognise that they are better placed to provide curated recommendations via artist tie-ins, along with explicit recommendations from users.
It’s also important to note here that these are all relatively well understood use cases - the learning curve here is much lower than, for example, explaining how a self driving car works.
If the problem you’re trying to solve is conceptually hard for users to understand then no matter how intelligent your product is, you’re still going to need to invest in educating users how a feature or product works.
If you can deliver on the outcomes your users value then maybe you don’t always need to explain the ‘how’ or the ‘why.