Let’s set the stage here: Data is the currency of competitive advantage in today’s digital age. As a consultant with extensive experience in the modernization and transformation space, I have seen many analysts struggle with their data due to the sheer variety of data types and number of different ways it can be shaped, packaged and evaluated.
Within any particular organization different teams can use different tools, different rule sets, and even different sources of truth to handle any particular data steward task. These operational differences lead to differing definitions of data and a siloed understanding of the ecosystem.
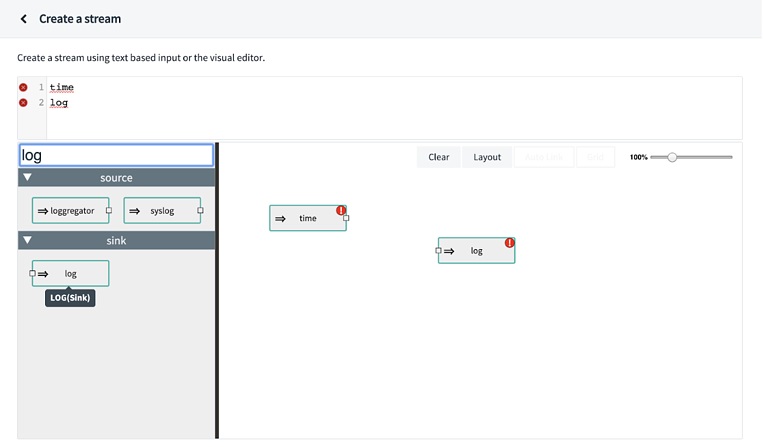
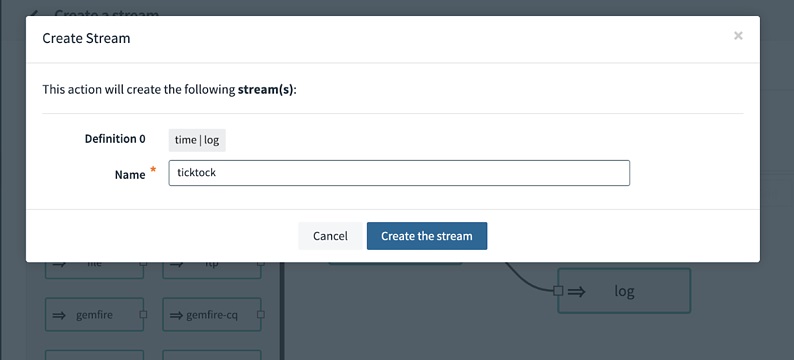
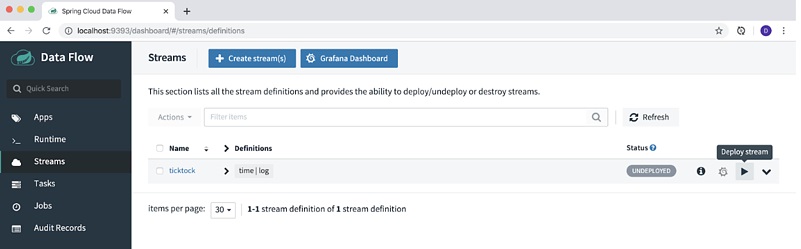
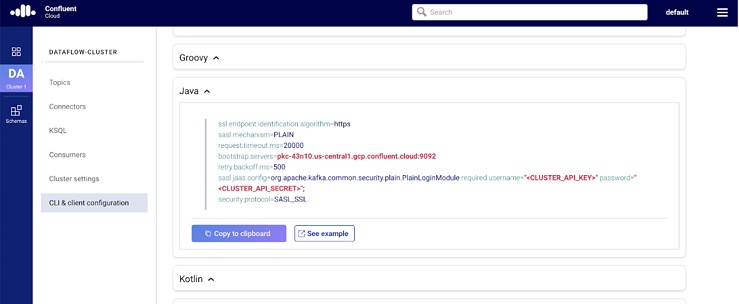
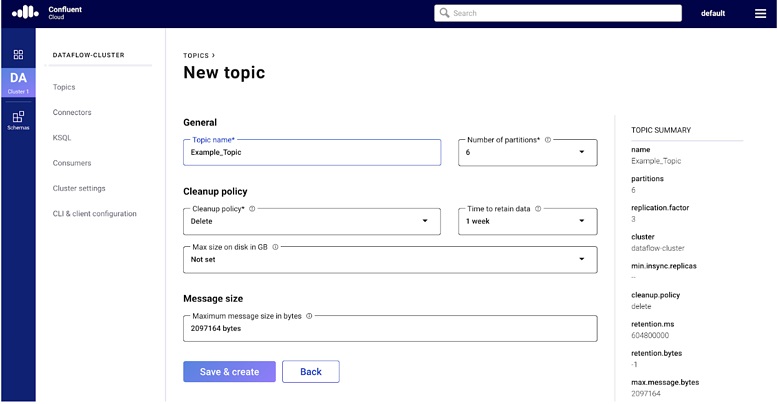
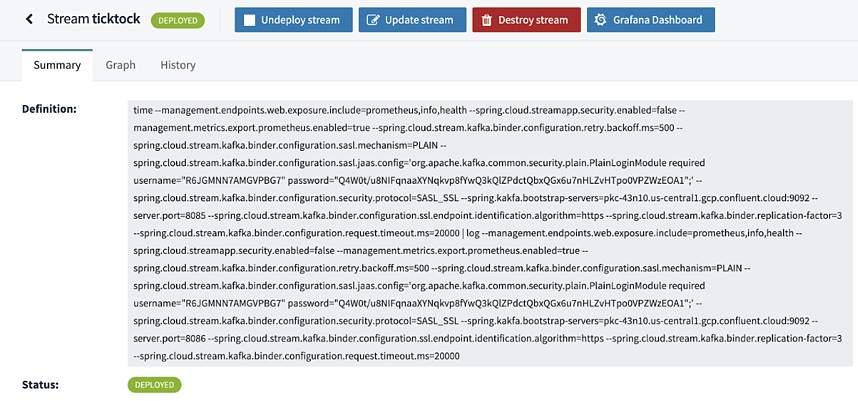
From the ashes of these battles have arisen several tools, some better than others. Most recently I’ve been working with Apache Kafka and Spring Cloud DataFlow to help transform my clients’ data ownership responsibilities, and at the same time, prepare them for the transition from batch to realtime.
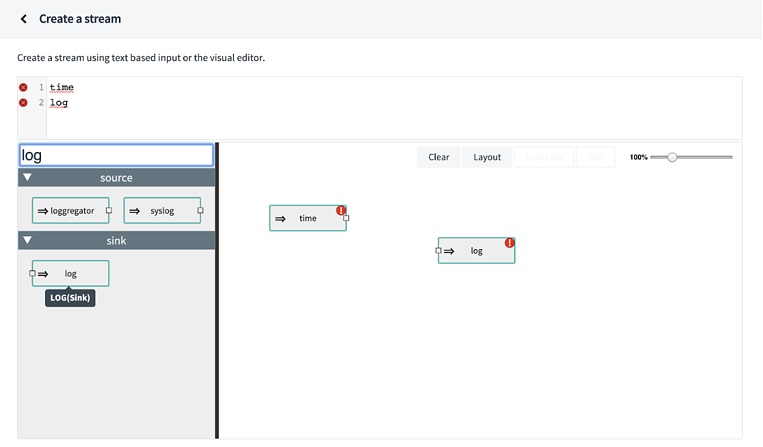
What follows is a step by step explanation of not only the process to use the tools, but why they were picked and what lessons were learned along the way. Follow along as we walk through the installation, configuration of Confluent Cloud and Spring Cloud DataFlow for development, implementation, and deployment of Cloud-Native data processing applications.
Prerequisites:
- An understanding of Java programming and Spring Boot application development.
- A knowledge of Docker and Docker Compose.
- An understanding of Publish / Subscribe messaging applications like Apache Kafka or RabbitMQ.
- Java 8 or 11 installed.
- An IDE or your favorite text editor (I see you out there vim / emacs lovers).
- Docker installed.
NOTE: All the following instructions, screenshots, and command examples are based on a Mac Pro running Catalina with 16GB of RAM. I wouldn’t recommend attempting to deploy Spring Cloud DataFlow locally with any less than 16 GB of RAM, as the setup does take a significant amount of resources.

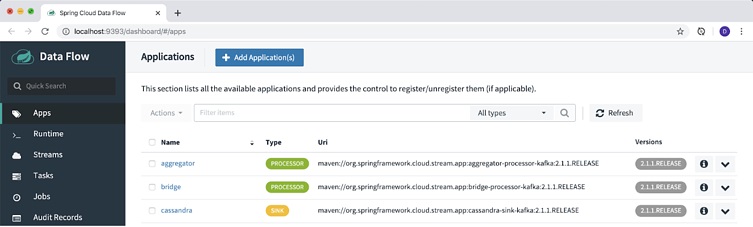
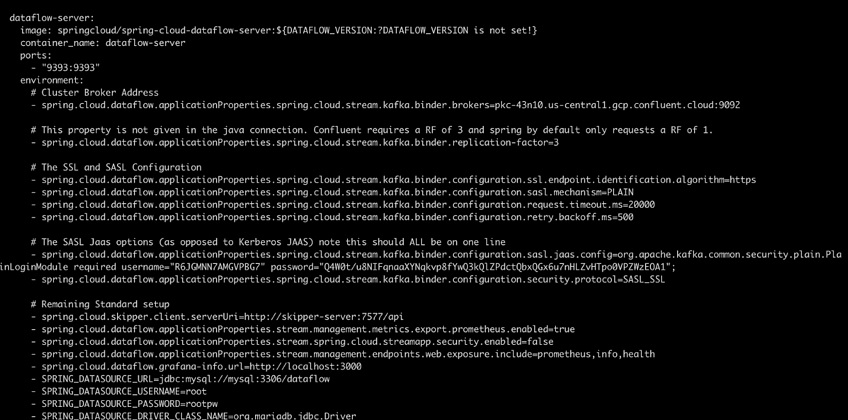
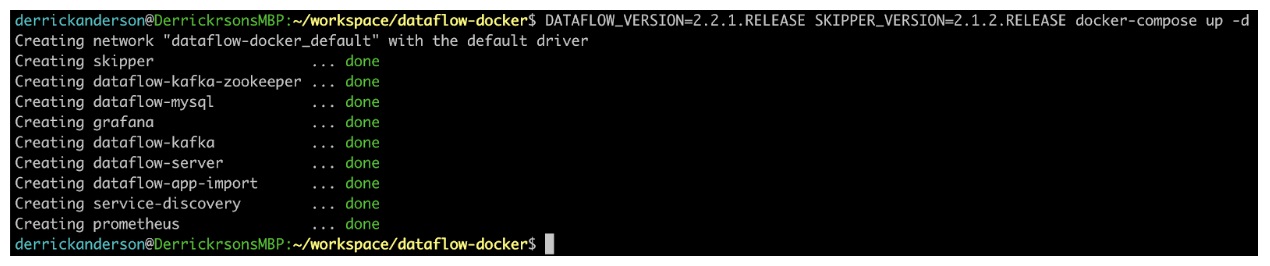 As you can see, there are several services that get created. The key parts are DataFlow-server and Skipper, which comprise the actual DataFlow experience and app deployment. Grafana and Prometheus, which are used for metric gathering and visualization, as well as Kafka and Zookeeper which is our messaging platform and the coordination server. I encourage you to review the documentation for DataFlows’ architecture located
As you can see, there are several services that get created. The key parts are DataFlow-server and Skipper, which comprise the actual DataFlow experience and app deployment. Grafana and Prometheus, which are used for metric gathering and visualization, as well as Kafka and Zookeeper which is our messaging platform and the coordination server. I encourage you to review the documentation for DataFlows’ architecture located